
A Minimal Deep Learning Library Implementation In Python
Published:
This tutorial introduces the main blocks needed to build a deep learning library in a few lines of Python. You'll learn how to build your (very) light-weight version of PyTorch!
Convolutional Neural Networks
We'll assume familiarity with Convolutional Neural Network (CNN) models. If not I strongly recommend you to first read Stanford's CS231n course on CNNs.
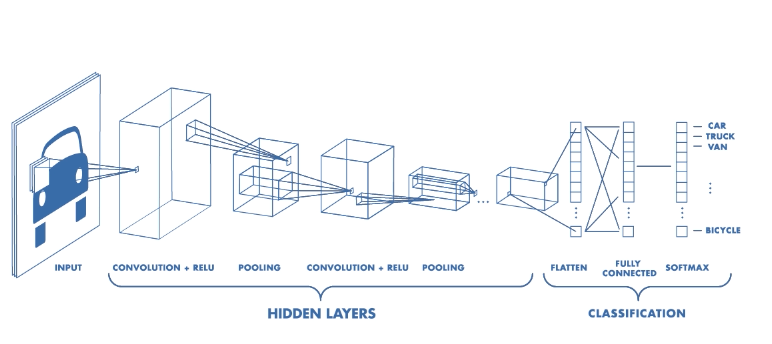
Architecture of a CNN. — Source: https://www.mathworks.com.
The module paradigm
The module inheritance paradigm underlies the widely used PyTorch, Sonnet and Gluon deep learning libraries.
The idea is to build neural networks in a hierarchical and factored way by leveraging the modularity of so-called modules.
From a mathematical perspective a module is a differentiable function. It can have parameters to be learned and then needs to also be differentiable with respect to these parameters.
From a programmatic perspective, it is a class implementing a forward method $\mathbf{y} = f(\mathbf{x})$ (input $\mathbf{x}$, output $\mathbf{y}$) and a backward method $g(\mathbf{x}, \nabla\mathbf{y}) = \nabla_{\mathbf{x}} \ f(\mathbf{x}) \times \nabla \mathbf{y}$. If it has parameters $\theta$ that we wish to learn, it additionally needs these parameters as attributes, a step method that performs an optimisation step on $\theta$ when called, and the backward method to also compute and save $\nabla_{\theta} f_\theta(\mathbf{x}) \times \nabla\mathbf{y}$ before returning $g(\mathbf{x}, \nabla\mathbf{y})$.
Below is the abstract Module class that will be inherited.
This design enables to build small blocks of layers than can then be assembled to build bigger blocks and so on. Factoring code in this manner reduces the number of lines needed to defined a model and eases experimentation of new architectures.
Layers
Layers are the basic functions composing neural networks. They will be implemented by inheriting the abstract Module class. For instance, a linear layer is parametrised by a weight $\mathbf{A}$ and a bias $\mathbf{b}$, and defined by the forward function $f(\mathbf{x}) = \mathbf{A} \mathbf{x} + \mathbf{b}$, the backward function $g(\mathbf{x}, \nabla\mathbf{y}) = \nabla_{\mathbf{x}} \ f(\mathbf{x}) \times \nabla \mathbf{y} = \mathbf{A} \nabla \mathbf{y}$ and its weight and bias partial derivatives $\nabla_{\mathbf{b}} \ f_{\mathbf{A},\mathbf{b}}(\mathbf{x}) \times \nabla\mathbf{y} = 1^T \nabla\mathbf{y}$ and $\nabla_{\mathbf{A}} \ f_{\mathbf{A},\mathbf{b}}(\mathbf{x}) \times \nabla\mathbf{y} = \nabla\mathbf{y}^T \mathbf{x}$.
Training
Neural networks can be trained via back-propagation which is the application of the chain rule to the loss's gradient up to the neural net's layers parameters.
For easiness, we restrict ourselves to neural nets that can be represented as a composition of functions $f(\mathbf{x}) = f_n \circ \dots \circ f_1(\mathbf{x})$. It enables to represent explicitly the dependency between layers via a list. Some networks like ResNets are excluded by this assumption since they need the network to be represented as a DAG, but it's all right for our purpose.
Such composition of functions are implemented via a Sequential class constructed with a list of sub-modules. Then its forward method calls each sub-module's forward method, its backward calls in reverse order each sub-module's backward method, and its step method calls each trainable (having parameters to learn) sub-module's step method.
The network is trained so as to minimise a user-defined loss $L(\mathbf{X}, \mathbf{y}^{\text{true}}, \theta) = \sum_{i} l(f_{\theta}(\mathbf{x}_i), y{\text{true}}_i)$. The cross entropy is for instance widely used for classification tasks.
Hence, each trainable layer gets its parameters partial derivative automatically computed by backpropagating the loss's gradient through the sequence of layers: \begin{equation} \forall i=n,\dots,1 \quad \nabla_{\theta_i} L(\mathbf{X}, \mathbf{y}, \theta) = \nabla_{\theta_i} f_i(\mathbf{X}) \times \left( g_{i+1} \circ \dots \circ g_n \left(\nabla_{X} L \left(\mathbf{X}, \mathbf{y}, \theta\right) \right) \right) \end{equation}
Optimisation
The most straightforward optimisation scheme for neural networks is (momentum) stochastic gradient descent which applies the following update on the parameters $\theta$ \begin{equation} v_t = \gamma v_{t-1} + \eta \nabla_\theta J( \theta) \\ \theta = \theta - v_t \end{equation} with $\eta$ being the learning rate and $\gamma$ the momentum coefficient. SGD inherits from Optmizer as implemented below.
I also implemented Adam and RMSProp in optim.py. For a nice review of gradient-based optimisation schemes used for deep neural nets training, check S. Ruder's blog post.
An optimisation step can then be performed by calling
Demonstration on MNIST
Let's demonstrate our library on the MNIST classification task dataset. We define our CNN by inheriting the Module class, thus implementing the forward, backward and step methods as shown below.
Clone the associated Github repository and then run the example script so as to load the MNIST dataset, instantiate the CNN model, train it by backpropagation and eventually predict a digit's label as plotted below.
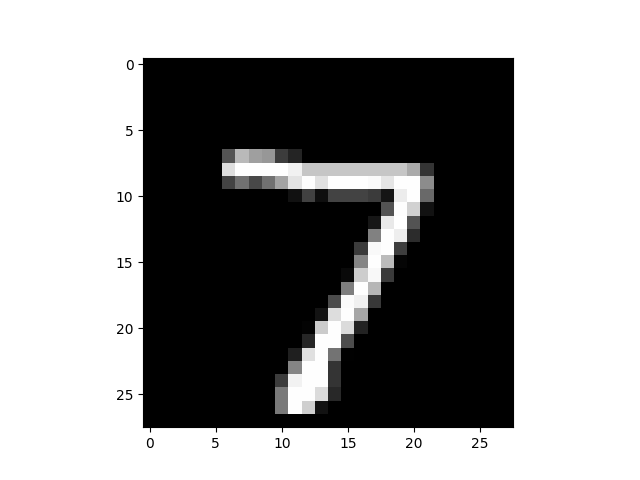
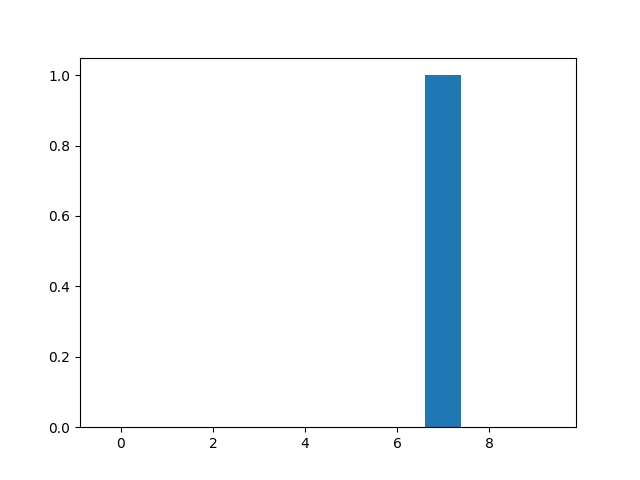
(Left) Example of mnist digit. (Right) Label prediction of our trained CNN.
What's missing towards a complete library ?
We've built in this tutorial the minimum blocks towards a working deep learning library, yet some parts are still missing to have a complete library. First, an automatic-differentation (autodiff) library avoid having to explicitly manipulate the gradients. Indeed, while being (imperatively) defined, the neural net is then implicitly represented as a DAG, allowing gradients to be automatically computed in a backward manner via the chain rule. Moreover, a data-loader wrapper is really useful so as to ease downloading, loading and preprocessing datasets. More layers and optimisation schemes should also be added. GPU support is also really important for large scale training.
Acknowledgments
I’m grateful to Thomas Pesneau and Yuan Zhou for their comments.